2016-11-6 代码更新
main.py
# -*- coding: utf-8 -*-
import urllib.request
import re
import hrefs
import GetContent
import SendCloud
from bs4 import BeautifulSoup
home_path = "/home/GetJWCInfo"
# 获取最新列表,按行存入文件
page = urllib.request.urlopen('http://jwc.jmu.edu.cn/class_show.asp?fid=1')
pages = BeautifulSoup(page, "html.parser", from_encoding="gbk")
hrefs_new = pages.find_all(href=re.compile("doc_show.asp"))
for i in range(0, 10):
hrefs_new[i] = hrefs_new[i].get('href') + "\n" # 提取获取到<a>的href
num = ((hrefs_new[0])[-5:])[:4]
# 打开链接存储文件,按行读取存入数组
hrefs_bak_out = hrefs.read(home_path+'/hrefs')
# 判断是否有新通知
if hrefs_new == hrefs_bak_out:
print("Matched.")
status = 0
else:
print("Not Matched.")
status = 1
# 新通知类型处理
if status == 0:
print("No New Notification Created.")
elif status == 1:
if hrefs_new[1] == hrefs_bak_out[0]:
print("One New Notification.")
hrefs.write(home_path+'/hrefs', hrefs_new)
fetch = GetContent.get(num)
title = fetch[0]
content = fetch[1]
attachment = fetch[2]
SendCloud.send('505646850@qq.com', 'send_jwcnotify', num, title, content, attachment)
elif hrefs_new[1] != hrefs_bak_out[0]:
print("More than One New Notification.")
SendCloud.send('505646850@qq.com', 'jwc_hrefsChanged', num, '', '', '')
hrefs.write(home_path+'/hrefs', hrefs_new)
fetch = GetContent.get(num)
title = fetch[0]
content = fetch[1]
attachment = fetch[2]
SendCloud.send('505646850@qq.com', 'send_jwcnotify', num, title, content, attachment)
print("End Script.")
hrefs.py
# -*- coding: utf-8 -*-
def write(file, lists):
try:
file = open(file, 'w+')
file.writelines(lists)
finally:
file.close()
def read(file):
try:
file = open(file, 'r+')
return file.readlines()
finally:
file.close()
GetContent.py
# -*- coding: utf-8 -*-
import urllib.request
import re
from bs4 import BeautifulSoup
def get(num):
html = urllib.request.urlopen('http://jwc.jmu.edu.cn/doc_show.asp?bh='+num)
HttpMessage = html.info()
ContentType = HttpMessage.get('Content-Type')
# 判断是否为html,是则执行后续进程
if ContentType == "text/html":
print("----Start Get Content Process")
print(" HTML Page Get.")
bs = BeautifulSoup(html, "html.parser", from_encoding="gb2312")
title = bs.find_all("b")
content = bs.find_all("tr")
# 判断内容块tr位置
for i in range(0, 4):
content_judge = (content[i].text.replace(" ", "").replace("\n", ""))[:2]
if content_judge == "来源":
content_pos = i+1
# content_num = len(content)
attachment = "<br />"
title = title[0].text.replace(" ", "").replace(" ", "")
content = (content[content_pos]).text.replace(" ", "\n<br />")
flag = 1
# 判断是否能获取到页面内容,是则执行后续进程
if flag == 1:
hrefs = bs.find_all(href=re.compile("upload"))
hrefs_num = len(hrefs)
# 判断是否有附件,有则获取附件链接并格式化
if hrefs_num == 0:
flag = 2
attachment = "无"
else:
for i in range(0, hrefs_num):
href = hrefs[i].get('href')
attachment = attachment + "<a href='http://jwc.jmu.edu.cn" + href + "'>" + "http://jwc.jmu.edu.cn" + href + "</a>\n" + "<br />"
flag = 3
# 判断是否为非空页面,是则进入发送进程
if flag == 2 or flag == 3:
print(" Get Finished.")
print("----End Get Content Process")
return title, content, attachment
else:
print("Empty Notification.")
else:
print("Not HTML Page, skipped.")
SendCloud.py
# -*- coding: utf-8 -*-
import requests
import json
def send(email, template, num, title, content, attachment):
if template == "send_jwcnotify":
mail_url = "http://api.sendcloud.net/apiv2/mail/sendtemplate"
API_USER = 'xxxxxx'
API_KEY = 'xxx'
xsmtpapi = {
'to': [email],
'sub': {
'%num%': [num],
'%title%': [title],
'%content%': [content],
'%attachment%': [attachment],
}
}
params = {
"apiUser": API_USER,
"apiKey": API_KEY,
"templateInvokeName": template,
"xsmtpapi": json.dumps(xsmtpapi),
"from": "sendcloud@sendcloud.org",
"fromName": "SendCloud",
"subject": "集美大学教务处新通知"
}
r = requests.post(mail_url, data=params)
print("Mail Sent.")
elif template == "jwc_hrefsChanged":
mail_url = "http://api.sendcloud.net/apiv2/mail/sendtemplate"
API_USER = 'xxx'
API_KEY = 'xxxxxx'
xsmtpapi = {
'to': [email],
'sub': {
'%num%': [num],
}
}
params = {
"apiUser": API_USER,
"apiKey": API_KEY,
"templateInvokeName": template,
"xsmtpapi": json.dumps(xsmtpapi),
"from": "sendcloud@sendcloud.org",
"fromName": "SendCloud",
"subject": "集美大学教务处新通知"
}
r = requests.post(mail_url, data=params)
print("Mail Sent.")
上一篇写了教务系统的登录,不算真正意义上的爬虫。
这一篇大部分都是爬虫,加上用SendCloud发送邮件的部分内容。
前期准备:
- 了解教务新通知链接模式
- 了解教务通知页面的结构
逻辑实现:
- 使用过Python抓取内容并格式化
- 通过SendCloud进行通知发送
首先,我们来了解一下学校教务处的通知页面。http://jwc.jmu.edu.cn/class_show.asp?fid=1

随便打开一条,观察地址。

可以看到很明显的一个部分:bh=xxxx,很好理解,bh就是编号的意思,代表这条通知的编号是5225。
那么我们就可以知道通知的模式是“(url)/doc_show.asp?bh=xxxx”此处用url代替前面部分的链接。
接着点开一个相邻的通知,继续观察链接。

现在可以暂时推断出,教务通知的编号是递增的,为我们后期获取新通知打下了基础。
下一步,观察整个页面。
此处不提供图…页面内标题被<b>包裹,内容被<p>包裹,附件链接被<a>包裹。标题为b[0],内容为p[0~],附件链接为a[0~]。
一个基本的思路已经出来了,使用Python访问通知页面→抓取第一个<b>标签内容作为标题→抓取所有<p>的内容作为通知内容。
那么开始代码实现,再次使用BeautifulSoup。
html = urllib.request.urlopen('http://jwc.jmu.edu.cn/doc_show.asp?bh=5255')
bs = BeautifulSoup(html, "html.parser", from_encoding="gbk")
title = bs.find_all("b")
content = bs.find_all("p")
content_num = len(content)
attachment = "<br />"
# 对标题和内容格式化
title = title[0].text.replace(" ", "").replace(" ", "")
for i in range(0,content_num):
content_text = content_text + content[i].text.replace(" ", "").replace(" ", "").replace(" ","") + "\n" + "<br />"
这样我们就直接获得了我们想要的内容。但是随着使用,发现了更多的问题。
- 通知推送的编号出现乱序或跳号
- (*)通知一次新增两条
- 通知内容为空,只有一个附件
- 通知直接链接到一个文件,无法作为页面读取
- 通知只含内容,不含附件链接
第一个问题,我的解决方法是,先获取一次首页所有通知的编号,存在一个文件中,然后通过每次对比是否一致来找出是否有新通知。
号码不递增分两种情况,比上一条通知大或比下一条通知小,如果小于则先获取新的一条,再回过头继续等待递增的下一条通知。
实现代码如下:
# -*- coding: utf-8 -*-
import urllib.request, re, os
from bs4 import BeautifulSoup
# 获取最新列表
page = urllib.request.urlopen('http://jwc.jmu.edu.cn/class_show.asp?fid=1')
pages = BeautifulSoup(page, "html.parser", from_encoding="gbk")
hrefs_new = pages.find_all(href=re.compile("doc_show.asp"))
# 打开链接存储文件,按行读取存入数组
hrefs_bak = open('/home/GetJWCInfo/href','r+')
hrefs_bak_out = hrefs_bak.readlines()
hrefs_bak.close()
# 对数据进行格式处理
for i in range(0, 10):
hrefs_new[i] = hrefs_new[i].get('href') # 提取获取到<a>的href
hrefs_bak_out[i] = hrefs_bak_out[i].replace("\n", "") # 去除换行符
# 判断是否有新通知
if hrefs_new == hrefs_bak_out:
print("Matched.")
status = 0
else:
status = 1
# 新通知类型处理
if status == 0:
print("No New Notification Created.")
elif status == 1:
if hrefs_new[1] == hrefs_bak_out[0]:
status = 2
print("One New Notifacation.")
num1 = (hrefs_new[0])[-4:]
num2 = (hrefs_bak_out[0])[-4:]
if int(num1) < int(num2): num = open('/home/GetJWCInfo/num_s', 'w') num.write(str(num1)) num.close() os.rename("/home/GetJWCInfo/num","/home/GetJWCInfo/num.bak") os.rename("/home/GetJWCInfo/num_s","/home/GetJWCInfo/num") os.system("python /home/GetJWCInfo/send_email.py") os.rename("/home/GetJWCInfo/num","/home/GetJWCInfo/num_s") os.rename("/home/GetJWCInfo/num.bak","/home/GetJWCInfo/num") elif int(num1) > int(num2):
num = open('/home/GetJWCInfo/num', 'w')
num.write(str(num1))
num.close()
os.system("python /home/GetJWCInfo/send_email.py")
for i in range(0, 10):
hrefs_new[i] = str(hrefs_new[i]+"\n")
hrefs_bak = open('/home/GetJWCInfo/href', 'w+')
hrefs_bak.writelines(hrefs_new)
hrefs_bak.close()
print("End Script.")
第二个问题,因为设定了每分钟获取,现在暂时还未碰到这种情况,所以暂时不重新改代码。
第三个问题,可以在一开始将content设为“无”,有内容时在开头添加一个换行符,即可解决这个问题。代码如下:
# 判断内容块是否为空,是则为无
if content_num == 0:
content_text = "无"
else:
content_text = "<br />"
第四个问题,通过读取目标页面类型,判断是否为html页面,可以避免无用的抓取,代码如下:
html = urllib.request.urlopen('http://jwc.jmu.edu.cn/doc_show.asp?bh='+num1_text)
HttpMessage = html.info()
ContentType = HttpMessage.get('Content-Type')
# 判断是否为html,是则执行后续进程
if ContentType == "text/html":
print("HTML Page Get.")
第五个问题,通过判断是否有<a>来处理,方法与第三个类似,并且得到的链接需要进行格式化,代码如下:
# 判断是否有附件,有则获取附件链接并格式化
if hrefs_num == 0:
flag = 2
attachment = "无"
else:
for i in range(0, hrefs_num):
attachment = attachment + "http://jwc.jmu.edu.cn" + hrefs[i].get('href') + "\n" + "<br />"
flag = 3
最后,进入发送进程。
# 判断是否为非空页面,是则进入发送进程
if flag == 2 or flag == 3:
mail_url = "http://api.sendcloud.net/apiv2/mail/sendtemplate"
API_USER = 'xxxxxx'
API_KEY = 'xxxxxxxxxx'
xsmtpapi = {
'to': ['aaaaaa@qq.com'],
'sub': {
'%num%': [num1_text],
'%title%': [title],
'%content%': [content_text],
'%attachment%': [attachment],
}
}
params = {
"apiUser": API_USER,
"apiKey": API_KEY,
"templateInvokeName": "send_jwcnotify",
"xsmtpapi": json.dumps(xsmtpapi),
"from": "sendcloud@sendcloud.org",
"fromName": "SendCloud",
"subject": "集美大学教务处新通知"
}
r = requests.post(mail_url, data=params)
print("Get Finished.")
else:
print("Empty Notification.")
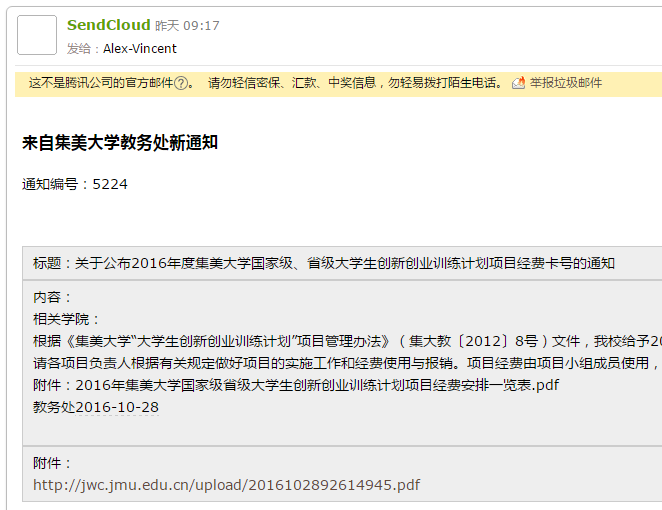
至此,整个获取通知到发送的过程已完成。效果图如图所示:
附上目录结构和所有代码:
get_page.py
# -*- coding: utf-8 -*-
import urllib.request, re, os
from bs4 import BeautifulSoup
# 获取最新列表
page = urllib.request.urlopen('http://jwc.jmu.edu.cn/class_show.asp?fid=1')
pages = BeautifulSoup(page, "html.parser", from_encoding="gbk")
hrefs_new = pages.find_all(href=re.compile("doc_show.asp"))
# 打开链接存储文件,按行读取存入数组
hrefs_bak = open('/home/GetJWCInfo/href','r+')
hrefs_bak_out = hrefs_bak.readlines()
hrefs_bak.close()
# 对数据进行格式处理
for i in range(0, 10):
hrefs_new[i] = hrefs_new[i].get('href') # 提取获取到<a>的href
hrefs_bak_out[i] = hrefs_bak_out[i].replace("\n", "") # 去除换行符
# 判断是否有新通知
if hrefs_new == hrefs_bak_out:
print("Matched.")
status = 0
else:
status = 1
# 新通知类型处理
if status == 0:
print("No New Notification Created.")
elif status == 1:
if hrefs_new[1] == hrefs_bak_out[0]:
status = 2
print("One New Notifacation.")
num1 = (hrefs_new[0])[-4:]
num2 = (hrefs_bak_out[0])[-4:]
if int(num1) < int(num2):
num = open('/home/GetJWCInfo/num_s', 'w')
num.write(str(num1))
num.close()
os.rename("/home/GetJWCInfo/num","/home/GetJWCInfo/num.bak")
os.rename("/home/GetJWCInfo/num_s","/home/GetJWCInfo/num")
os.system("python /home/GetJWCInfo/send_email.py")
os.rename("/home/GetJWCInfo/num","/home/GetJWCInfo/num_s")
os.rename("/home/GetJWCInfo/num.bak","/home/GetJWCInfo/num")
elif int(num1) > int(num2):
num = open('/home/GetJWCInfo/num', 'w')
num.write(str(num1))
num.close()
os.system("python /home/GetJWCInfo/send_email.py")
for i in range(0, 10):
hrefs_new[i] = str(hrefs_new[i]+"\n")
hrefs_bak = open('/home/GetJWCInfo/href', 'w+')
hrefs_bak.writelines(hrefs_new)
hrefs_bak.close()
print("End Script.")
send_email.py
# -*- coding: utf-8 -*-
import urllib.request, requests, json, re
from bs4 import BeautifulSoup
num1 = open('/home/GetJWCInfo/num')
try:
num1_text = num1.read()
finally:
num1.close()
html = urllib.request.urlopen('http://jwc.jmu.edu.cn/doc_show.asp?bh='+num1_text)
HttpMessage = html.info()
ContentType = HttpMessage.get('Content-Type')
# 判断是否为html,是则执行后续进程
if ContentType == "text/html":
print("HTML Page Get.")
bs = BeautifulSoup(html, "html.parser", from_encoding="gbk")
title = bs.find_all("b")
content = bs.find_all("p")
content_num = len(content)
attachment = "<br />"
# 判断内容块是否为空,是则为无
if content_num == 0:
content_text = "无"
else:
content_text = "<br />"
# 对标题和内容格式化
try:
title = title[0].text.replace(" ", "").replace(" ", "")
for i in range(0,content_num):
content_text = content_text + content[i].text.replace(" ", "").replace(" ", "").replace(" ","") + "\n" + "<br />"
flag = 1
except:
flag = 0
print("Unable to fetch new notification.")
# 判断是否能获取到页面内容,是则执行后续进程
if flag == 1:
hrefs = bs.find_all(href=re.compile("upload"))
hrefs_num = len(hrefs)
# 判断是否有附件,有则获取附件链接并格式化
if hrefs_num == 0:
flag = 2
attachment = "无"
else:
for i in range(0, hrefs_num):
attachment = attachment + "http://jwc.jmu.edu.cn" + hrefs[i].get('href') + "\n" + "<br />"
flag = 3
# 判断是否为非空页面,是则进入发送进程
if flag == 2 or flag == 3:
mail_url = "http://api.sendcloud.net/apiv2/mail/sendtemplate"
API_USER = 'xxxxxx'
API_KEY = 'xxxxxxxxxx'
xsmtpapi = {
'to': ['xxx@xx.com'],
'sub': {
'%num%': [num1_text],
'%title%': [title],
'%content%': [content_text],
'%attachment%': [attachment],
}
}
params = {
"apiUser": API_USER,
"apiKey": API_KEY,
"templateInvokeName": "send_jwcnotify",
"xsmtpapi": json.dumps(xsmtpapi),
"from": "sendcloud@sendcloud.org",
"fromName": "SendCloud",
"subject": "集美大学教务处新通知"
}
r = requests.post(mail_url, data=params)
print("Get Finished.")
else:
print("Empty Notification.")
else:
print("Not HTML Page, skipped.")